
TL;DR - 11 concurrent real-time streams on a single RTX 4090 Laptop 16 GB (~77 W average draw), de-synchronized, not a batch-aligned best case. - Out of the box, the model does not even fit on a 16 GB GPU: the default serving config OOMs at boot. - The root cause is conceptual: a streaming session runs out of RoPE positions, not memory. Mistral’s own model card says so. - The fix is an optional, default-off RoPE re-anchoring: unbounded streaming at constant VRAM. Plus three production-blocking bugs fixed along the way. - Running in production today at LINAGORA / LinTO.ai.
A stream that went quiet
A live transcription session was running fine, then stopped. The WebSocket stayed open, audio kept arriving, but no partial came out. No error, no disconnect, no crash: just silence on the wire, server-side, as if nothing were wrong.
That’s one of two ceilings stock vLLM hits running Voxtral-Mini-4B-Realtime. Chasing it led to an upstream contribution that makes the model genuinely self-hostable on a single 16 GiB GPU and, behind a flag, lets a session run as long as you want at constant VRAM. What follows: the bug, the fix, the numbers, and what they say about the state of “open” model releases.
The insight: you run out of positions, not memory
A real-time speech model is, from the engine’s point of view, one sequence that never ends. Audio arrives, tokens append, the sequence grows. On a sliding-window decoder, the thing that grows without bound is not the KV cache: the window already pins per-stream KV to a constant. What grows is the position counter. RoPE (rotary position embedding) positions are absolute and bounded by --max-model-len.
So a streaming session doesn’t run out of memory, it runs out of positions.
This isn’t our reading of it: Mistral writes it on the model card, “In theory, you should be able to record with no limit; in practice, pre-allocations of RoPE parameters among other things limits –max-model-len.” The vendor itself puts the ceiling on RoPE, not memory, and tells you to size --max-model-len to the duration you plan to record. You have to pre-commit to a maximum recording length and pay the pre-allocation for it. They also concede the limit shouldn’t exist in theory. This fix is that theory made real: record with no limit, for real.
How limiting is that in practice? You hit it in minutes, not hours. The duration you pre-commit is exact: one token is 80 ms of audio, so your ceiling is --max-model-len × 0.08 s. And on a commodity 16 GB card you can’t just set it high: stock vLLM sizes the audio encoder’s boot-time profiling budget from --max-model-len, so a long value OOMs at startup before a single second is transcribed. The published recipe’s 45000 (exactly one hour) is validated on a 40 GB A100; the model’s hard ceiling of 131072 tokens is ~2 h 55 and wants datacenter silicon.

So out of the demo, “cap --max-model-len low enough to boot on the GPU you have” buys you minutes of audio per session, and the model’s full ~3 hours needs a rented datacenter card. The fix below removes the trade: duration stops costing VRAM, and stops costing you a bigger card.
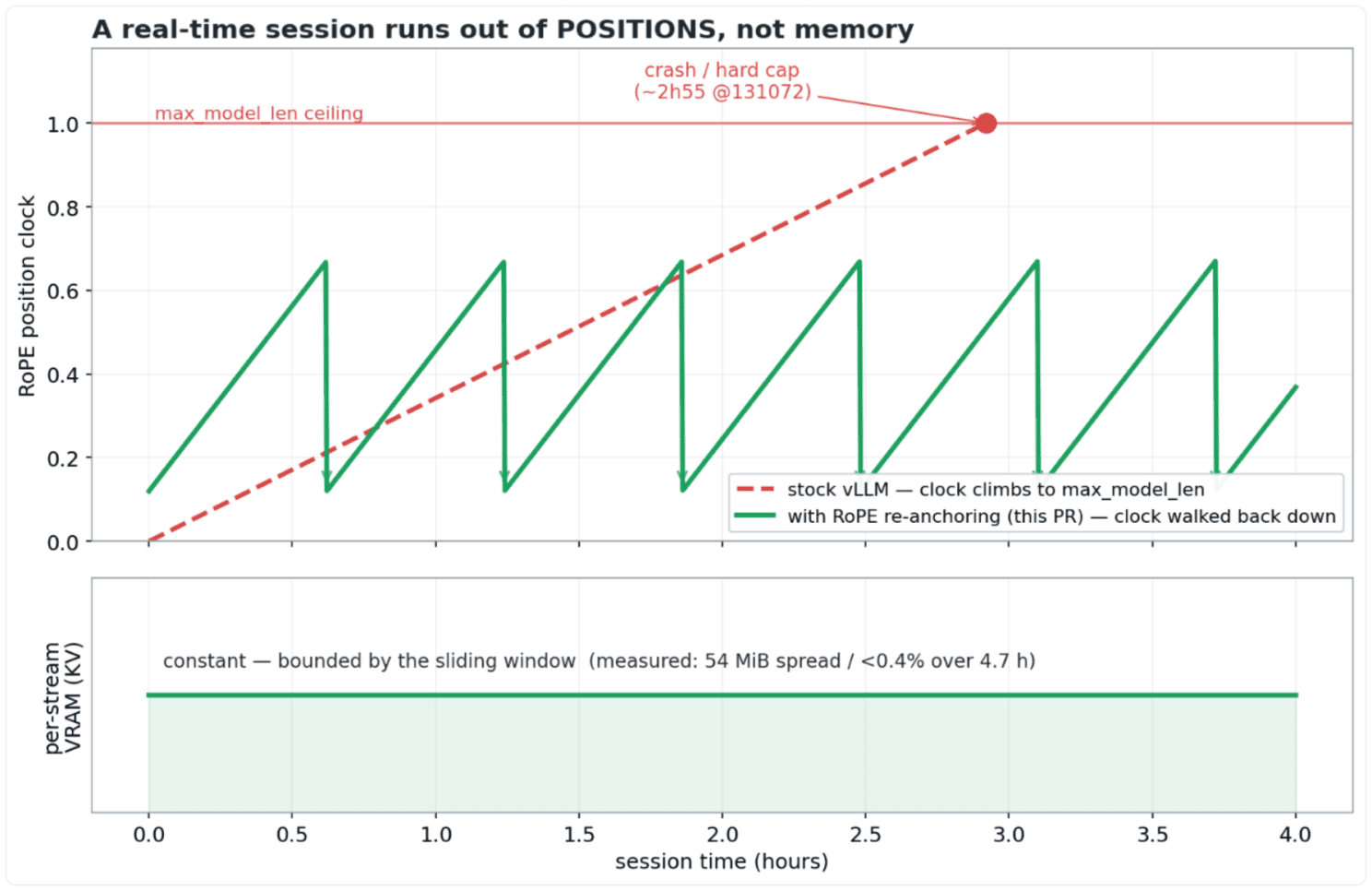
Once you frame it that way, the fix is simple. On a sliding-window decoder, a query at position m attends only to keys in (m−W, m], and an attention score depends only on the relative offset m−n. Shift every live position down by a constant D and every in-window score is preserved to the bit: nothing the model can still see depends on the absolute value of the clock.
In plain terms: just before the clock hits the ceiling, we quietly walk it back down, keeping intact everything the model can still see, and the session never notices. For implementers, the catch is where RoPE lands: vLLM caches keys after rotation, so the cache holds R(n)·k, not k. Re-anchoring can’t just decrement a counter; it has to re-rotate each live cached key by R(−D) (one precomputed complex-multiply per vector) to turn R(n)·k into R(n−D)·k. Queries regenerate fresh at the lower clock. So the clock walks back down before it ever reaches max_model_len, while per-stream KV stays constant. A rare event, only near the limit, gated behind a default-off flag; it does not apply to full-attention models, whose out-of-window keys are never evicted and which the shift would corrupt.
What it fixes on a plain 16 GiB GPU
Start with the part nobody puts on the slide: out of the box, Voxtral-Mini-4B-Realtime does not fit on a 16 GB GPU. With the default --max-model-len the encoder budget alone blows past the card at boot, and even with the context capped the default serving config OOMs capturing CUDA graphs sized for batches you’ll never run. So before duration is even on the table, stock vLLM fails self-hosting three ways: it OOMs at boot (the audio encoder budget scales with max_model_len and starves decoder KV), it freezes silently on a long silence, and it brings down the whole engine, so every concurrent session with it, when any one session reaches max_model_len. The PR fixes all three, then removes the duration ceiling. On 16 GB you also want to size the CUDA-graph capture to your real concurrency and let the allocator reclaim fragmentation; the serving doc spells out the exact flags.

The window is the concurrency lever
Per-stream KV is bounded by the attention window, not by max_model_len. So narrowing the window is a direct concurrency lever: it trades a little transcription fidelity for a lot of KV headroom. We swept it (re-anchor off, greedy, one 9-minute French clip), measuring transcript change against the default-window output, since there’s no human reference here for a real WER.

The recommended setting, 512/256, costs ~0.6% transcript change for ~3.3x the KV headroom, and the changes are surface-level (proper-noun spelling, plurals); the narrow window is sometimes more correct (the default window writes l'adnum, the narrow one la dinum, and DINUM is in fact the French digital-services agency). At a 256 decoder window the cost roughly triples (~1.9%): that’s the knee, and below it it keeps climbing. The encoder window, by contrast, is over-provisioned, and halving it costs almost nothing.
The numbers, no rounding up
- 4 concurrent real-time streams held for 4.7 hours on one RTX 4090 Laptop 16 GiB. VRAM moved 54 MiB (<0.4%), and that’s a one-time CUDA-graph capture at warmup, not a trend. Pace exactly real-time (wall/audio = 1.000 on all four), kv_usage flat at ~0.38 in the 4-stream steady state, a by-construction bounded count of re-anchor events, 0 errors. 4.7 h is the longest continuous run we measured; the mechanism itself is unbounded by construction.
- Re-anchoring does not degrade transcription, and it’s measured. An A/B test (re-anchor ON vs OFF, identical window and clip, re-anchoring the only variable) across four window topologies, including the trickiest merged-group case (256/256, 512/512): transcript change of 0.00% to 1.14%, no meaning substitutions, no repetition loops, 0 crashes, up to ~260 re-anchor events per 6-minute run. The one non-zero row is a single trailing phrase the client didn’t flush, not a corruption. The in-place R(−D) re-rotation of cached keys is transparent.
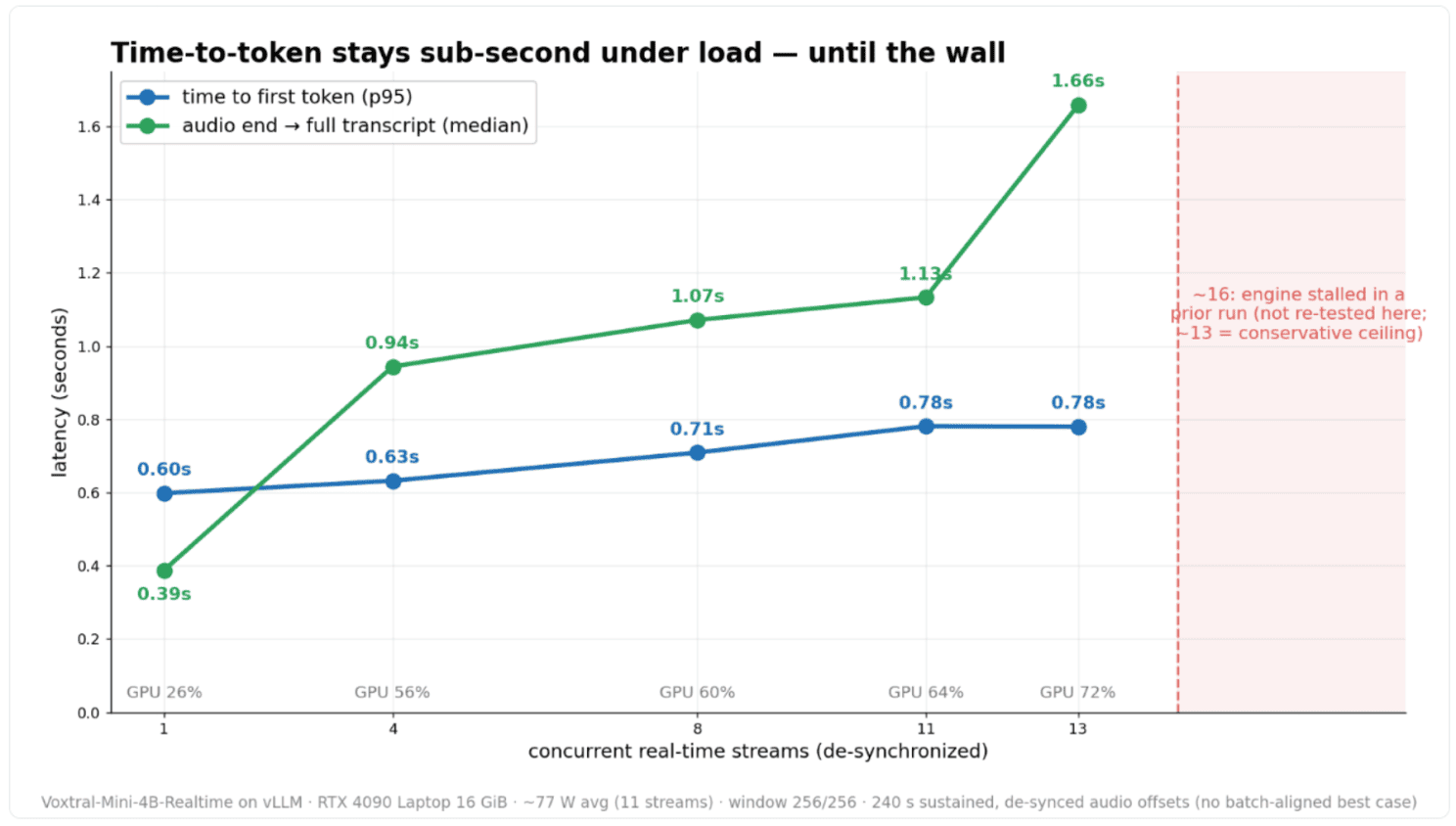
- A 1 to 13 de-synchronized stream ramp held real-time (each stream at a different point in the audio, not a batch-aligned best case), each level a 240 s real-time-paced run on the same 16 GiB laptop card: wall/audio ≤ 1.007, 0 errors, GPU rising ~26% to 72% at ~77 W average draw (11 streams).
- Time-to-token stayed sub-second across the whole range, and that’s the metric that actually matters: first token from about 0.6 to 0.8 s, audio-end to full transcript from about 0.4 to 1.7 s, from 1 to 13 streams. It degrades gracefully, no cliff: vLLM’s continuous batching packs the streams beautifully and the 4B model is genuinely light. (Measured at the dense 256/256 window; the recommended production default 512/256 favors fidelity, and since this ramp was compute-bound the window moves fidelity, not stream count. This is minutes-per-level; the multi-hour point is the 4-stream / 4.7 h run above.)
- Nothing is dropped under load. At every ramp level each stream ran its full 240 s session with partials arriving throughout and a final transcript returned, 0 errors, wall/audio ≈ 1.0, so “real-time” here is the server keeping pace start to finish, not just at the first token. Each sequence decodes independently of its batch-mates, so a stream’s transcript under concurrency matches its solo transcript. We then ran the exact check on the shipped image: 4 concurrent identical-audio streams each returned the same 2222 words, zero spread, complete to the 15-minute mark, 0 errors.
- The quality result is preliminary: one 9-minute French clip; a human-reference WER pass comes next.
The capacity ceiling is real, and it’s a wall, not a slope. ~13 de-synced streams hold real-time (measured at 256/256); a prior session saw the engine stall near 16 on multi-session KV saturation, a pre-existing limit (in the base path, not the re-anchor feature) that this work doesn’t fully close. We treat ~13 as the conservative ceiling on this card and didn’t re-test 16; 11 stays comfortable. And the ceiling here is compute-bound, not memory-bound: VRAM stays flat (~15.4 GB) whether you run 1 stream or 13, because per-stream KV is pinned by the window. That’s the whole point: once memory stops being the cap, the stream count scales with the card’s compute. This laptop GPU holds ~11 to 13, a smaller card like the A4000 holds ~3 when well cooled, a bigger one more.
We also ran an adversarial, section-by-section review against current main for blast radius on non-Voxtral workflows: safe, with one pooling-at-max_model_len regression caught and fixed before merge, plus a regression test added.
The bigger picture: a note on open-source ecosystem health
Credit first, because it’s real. Voxtral realtime is genuinely open (Apache 2.0), and vLLM support landed on day one: the realtime WebSocket API (PR #33187) was created Jan 27 and merged Jan 30, 2026, five days before launch, by the model’s own team and with member review. Fixes are still landing (transformers≥5.10 compat, #44559, merged this week). A 4B Apache-2.0 audio model with upstreamed realtime serving on launch day is an uncommon, real commitment. None of what follows imputes intent to anyone.
But “runs on a single 16 GB GPU” describes the single-stream demo, not production, and the gap comes down to three things. This is less a Voxtral story than a pattern that keeps recurring in how open models reach production, or don’t.
1. The recipes tell you to buy the wrong GPU. The published serving configs converge on one command: Red Hat’s day-1 guide and the matching community cheat-sheet carry the same line verbatim, --max-model-len 45000 --max-num-batched-tokens 8192 --max-num-seqs 16 --gpu-memory-utilization 0.90, tested on an A100. Look at the shape: it never narrows the window and pairs a wide per-step batch with sixteen sequences, scaling the card up instead of bounding each stream’s cost. On a sliding-window decoder, per-stream KV should be pinned by the window, not widened by the batch budget and multiplied across sixteen streams. Follow that recipe for real concurrency and you’re pushed onto a datacenter GPU. The community’s own multi-stream benchmark concluded you need “something better than a single RTX 4090,” and three open issues (#38233, #39996, #38428) show multi-session / long-session runs crashing the engine instead of degrading gracefully.
2. And that’s the part with a real bill, financial and ecological. We measured the other end of that spectrum above: eleven live streams under 80 watts on this 16 GB laptop card, de-synchronized, each holding real-time, set against a reference recipe validated on an A100 and a community benchmark that concluded you need “something better than a single RTX 4090.” Bounding the per-stream KV by the sliding window is what makes the same concurrency fit on a commodity card instead of a datacenter one: roughly an order of magnitude in GPU cost and several times the power draw, per node, multiplied across every team that copy-pastes the recipe. Capex you didn’t need, watts you didn’t need to burn, silicon that didn’t need to be manufactured. At fleet scale, a default that over-provisions is a standing tax on both the budget and the grid. The flip side is a genuine compliment to the stack: that ~77 W is even possible comes down to a lean 4B model and vLLM’s continuous batching doing its job beautifully. The waste isn’t inherent; it’s in the default that tells you to size for the worst case. (Cost and power figures are orders of magnitude, illustrative; the point is the direction.)
3. The fixes that would close the gap have sat open. As of early June: #36015 (silent hang) open since March, triaged within hours but with no maintainer-authored fix shipped; a community fix #36089 closed unmerged, its author noting “7+ weeks with no maintainer review despite a follow-up ping”; #40072 (the max_model_len crash) open since April with only an automated review, a third-party noting it sat ~5 weeks behind a first-time-contributor CI gate “with no maintainer label.” These defects live in vLLM, a volunteer, community-governed project, not Mistral’s code (the merged realtime path is Mistral’s). It’s a review-throughput problem, not malice. But the outcome is the same: the production fixes are in limbo, while the same model is sold on a hosted API (~$0.003 to $0.006/min) that just works.
That’s the recurring shape of “open” releases: launch-day polish on one side, production-readiness and its hardware bill on the other, left as an exercise for the reader. The honest answer isn’t a complaint thread: it’s a patch, upstreamed, coordinated with the people already on those threads. That’s what we did.
While it waits to merge, and a call to contribute
We’re not sitting on our hands: this fork already runs in production at LINAGORA, powering real-time transcription on our open-source LinTO.ai platform. But its home is upstream, and that’s where you can help:
- Try the fork. Boot it with the bounded config (--hf-overrides sliding_window + the unbounded flag) and report how it behaves on your hardware and your audio, especially multi-stream and long-duration.
- Review it. That’s exactly what it needs, because it touches sensitive core-engine paths: the scheduler’s WAITING/RUNNING request loop and length-cap gating (shared by every model), the sliding-window KV-cache admission, and the delicate one, re-rotating already-cached KV keys in place by R(−D) on the worker, plus decoupling the RoPE position clock from max_model_len. That blast radius is exactly why it’s gated default-off and why it needs to clear vLLM’s RFC bar.
- Push it through. A 👍, a real-world usage note on the issues (#36015, #40072) and on the PR genuinely helps it clear the RFC. An open issue stays open until people show it matters.
Fork : https://github.com/linto-ai/vllm ·
vLLM PR : https://github.com/vllm-project/vllm/pull/45022
docker pull lintoai/vllm:voxtral-realtime ·
LinTO.ai : https://linto.ai
Sources
- Voxtral announcement (Mistral, Feb 4, 2026) : https://mistral.ai/news/voxtral-transcribe-2/ · Pricing : https://mistral.ai/pricing/
- Model card (Hugging Face) : https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602
- vLLM recipe : https://recipes.vllm.ai/mistralai/Voxtral-Mini-4B-Realtime-2602 ·
Red Hat day-1 guide: : https://developers.redhat.com/articles/2026/02/06/run-voxtral-mini-4b-realtime-vllm-red-hat-ai ·
dougbtv cheat-sheet : https://gist.github.com/dougbtv/f27d05fd6de68e07be3651c453bf37c7 - vLLM PRs: #33187 (realtime API, merged) · #44559 (compat, merged) · #36089 (closed, unmerged) · #40072 (open) · #44461 (open)
- vLLM issues: #36015 · #35863 · #38233 · #38428 · #39996