
En bref - 11 flux temps réel simultanés sur une seule RTX 4090 Laptop 16 Go (~77 W de moyenne), désynchronisés, pas un cas idéal où les batches s’alignent. - En l’état, le modèle ne rentre même pas sur un GPU de 16 Go : la config de serving par défaut sature la mémoire dès le démarrage. - La cause est conceptuelle : une session de streaming épuise ses positions RoPE, pas sa mémoire. Mistral l’écrit dans sa propre fiche modèle. - Le correctif est un ré-ancrage RoPE, optionnel et désactivé par défaut : du streaming sans limite de durée, à VRAM constante. Et trois bugs qui bloquaient en production, corrigés au passage. - En production aujourd’hui chez LINAGORA / LinTO.ai.
Un flux devenu muet
Une session de transcription en direct tournait sans accroc, puis s’est arrêtée. La WebSocket restait ouverte, l’audio continuait d’arriver, mais plus aucune transcription partielle ne sortait. Aucune erreur, aucune déconnexion, aucun plantage : juste le silence sur le fil, côté serveur, comme si de rien n’était.
C’est l’un des deux plafonds que vLLM vient heurter, en l’état, avec Voxtral-Mini-4B-Realtime.
Traquer ce plafond nous a menés à une contribution en amont : elle rend ce superbe modèle vraiment auto-hébergeable sur un seul GPU de 16 Go et, derrière un simple flag vLLM, laisse une session tourner aussi longtemps qu’on veut, à VRAM constante. Je détaille plus bas le bug, le correctif, les mesures, et ce qu’ils disent de l’état des modèles publiés en « ouvert ».
Le déclic : ce qui s’épuise, ce sont les positions, pas la mémoire
Un modèle de parole temps réel, du point de vue du moteur, c’est une seule séquence qui ne se termine jamais. L’audio arrive, les tokens s’ajoutent, la séquence s’allonge. Sur un décodeur à fenêtre glissante, ce qui grossit sans fin n’est pas le cache KV : la fenêtre borne déjà la KV par flux à une constante. Ce qui grossit, c’est le compteur de positions. Les positions RoPE (rotary position embedding) sont absolues, et plafonnées par la directive --max-model-len.
Une session de streaming ne manque donc pas de mémoire, elle manque de positions.
Ce n’est pas notre interprétation : Mistral l’écrit dans la fiche du modèle sur HuggingFace, « In theory, you should be able to record with no limit; in practice, pre-allocations of RoPE parameters among other things limits –max-model-len. » L’éditeur place donc lui-même le plafond du côté de RoPE, pas de la mémoire, et demande de dimensionner --max-model-len sur la durée qu’on compte enregistrer. Il faut pré-engager une durée maximale, et en payer la pré-allocation. Mistral reconnaît d’ailleurs qu’en théorie ce plafond ne devrait pas exister. Le correctif, c’est cette théorie rendue réelle : enregistrer sans limite, pour de bon.
Concrètement, à quel point est-ce limitant ? On le heurte en minutes, pas en heures. La durée qu’on pré-engage est exacte : un token vaut 80 ms d’audio, donc le plafond, c’est --max-model-len × 0,08 s. Et sur une carte grand public de 16 Go, on ne peut même pas le régler haut : vLLM stock dimensionne le budget de profilage de l’encodeur audio au démarrage à partir de --max-model-len, si bien qu’une valeur élevée sature la mémoire au boot, avant la moindre seconde transcrite. Le 45000 de la recette publiée (exactement une heure) est validé sur une A100 40 Go ; le plafond dur du modèle, 131072 tokens, fait ~2 h 55 et réclame des GPU Pro.

Donc hors démo, « plafonner --max-model-len assez bas pour démarrer sur le GPU qu’on a » n’achète que quelques minutes d’audio par session, et les ~3 h pleines du modèle exigent une carte de datacenter louée. Le correctif ci-dessous supprime cet arbitrage : la durée cesse de coûter de la VRAM, et cesse d’exiger une carte plus grosse.
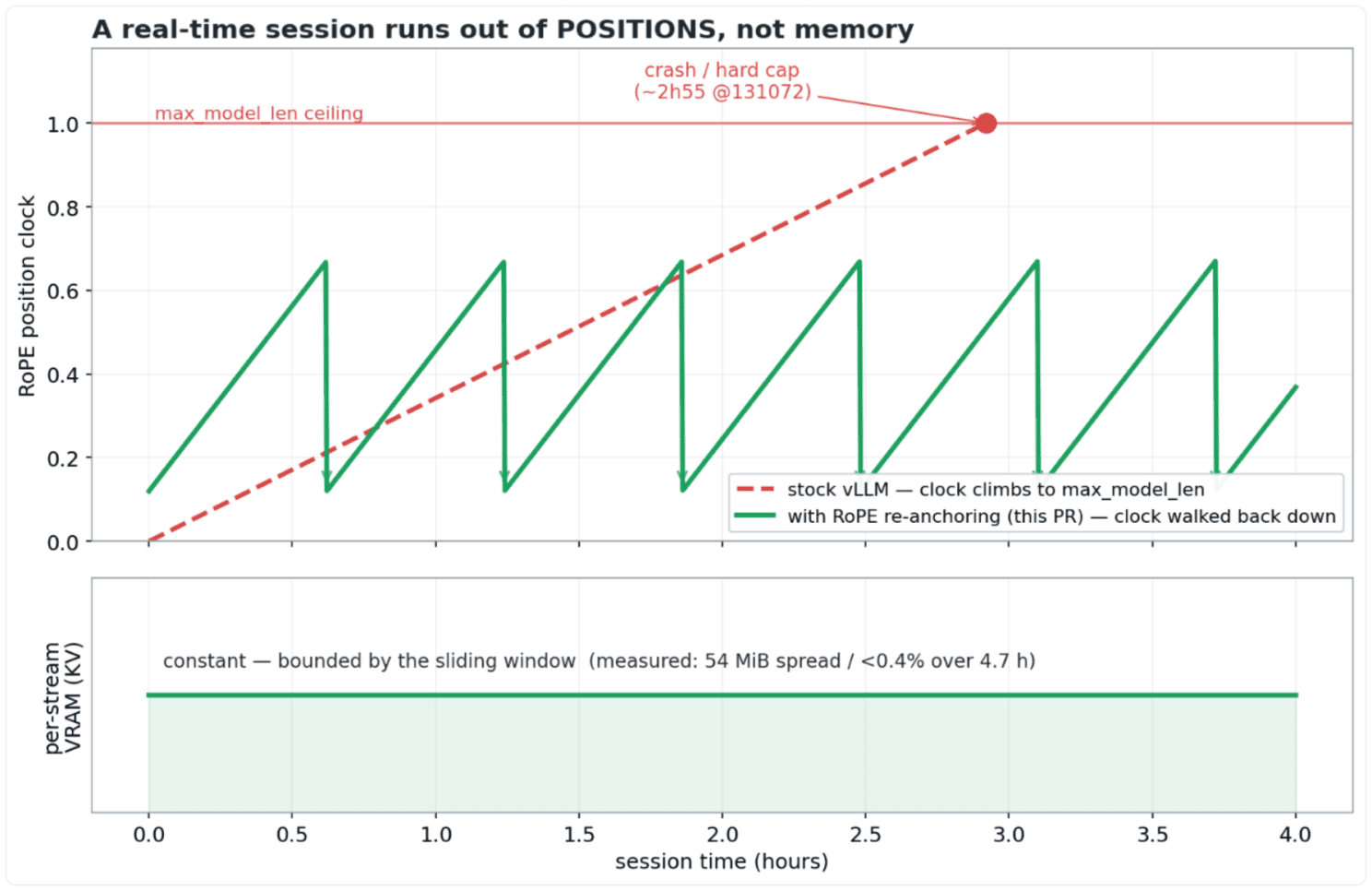
Une fois le problème posé comme ça, le correctif est simple. Sur un décodeur à fenêtre glissante, une requête en position m n’attend que les clés de l’intervalle (m−W, m], et un score d’attention ne dépend que de l’écart relatif m−n. Décalez toutes les positions vivantes d’une même constante D et chaque score à l’intérieur de la fenêtre reste identique au bit près : rien de ce que le modèle voit encore ne dépend de la valeur absolue de l’horloge.
Concrètement : juste avant que l’horloge n’atteigne le plafond, on la fait redescendre sans bruit, en gardant intact tout ce que le modèle voit encore, et la session ne s’aperçoit de rien. Pour qui veut l’implémenter, le piège est de savoir où RoPE intervient : vLLM met les clés en cache après rotation, le cache contient R(n)·k et non k. Le ré-ancrage ne peut donc pas juste décrémenter un compteur ; il faut re-tourner chaque clé vivante du cache par R(−D) (une multiplication complexe précalculée par vecteur) pour transformer R(n)·k en R(n−D)·k. Les requêtes, elles, repartent de la nouvelle horloge. L’horloge redescend donc avant d’avoir touché max_model_len, et la KV par flux reste constante. Événement rare, seulement à l’approche de la limite, gardé derrière un flag désactivé par défaut ; il ne s’applique pas aux modèles à attention pleine, dont les clés hors fenêtre ne sont jamais évincées et que le décalage corromprait.
Ce que ça répare sur un simple GPU de 16 Go
Commençons par ce que personne ne met sur le slide : en l’état, Voxtral-Mini-4B-Realtime ne rentre pas sur un GPU de 16 Go. Avec le --max-model-len par défaut, le seul budget de l’encodeur dépasse déjà la carte au démarrage ; et même contexte plafonné, la config de serving par défaut sature en capturant des graphes CUDA dimensionnés pour des lots qu’on ne fera jamais tourner. Donc avant même de parler de durée, vLLM rate l’auto-hébergement de trois façons : il sature au démarrage (le budget de l’encodeur audio croît avec max_model_len et affame la KV du décodeur), il se fige en silence sur un silence prolongé, et il fait tomber tout le moteur, donc toutes les sessions en cours, dès qu’une session atteint max_model_len. La PR corrige les trois, puis lève le plafond de durée. Sur 16 Go, il faut aussi caler la capture de graphes CUDA sur la concurrence réelle et laisser l’allocateur récupérer la fragmentation ; la doc de serving donne les flags exacts.

La fenêtre, c’est le levier de concurrence
La KV par flux est bornée par la fenêtre d’attention, pas par max_model_len. Rétrécir la fenêtre est donc un levier direct sur la concurrence : on échange un peu de fidélité de transcription contre beaucoup de marge KV. On a balayé le réglage (ré-ancrage désactivé, greedy decoding, un extrait français de 9 minutes), en mesurant le taux de changement de la transcription par rapport à la sortie à fenêtre par défaut, faute de référence humaine pour un vrai WER.

Le réglage recommandé, 512/256, coûte ~0,6 % de changement de transcription pour ~3,3× de marge KV, et les écarts restent de surface (orthographe des noms propres, pluriels) ; la fenêtre étroite est même parfois plus juste (la fenêtre par défaut écrit l'adnum, l’étroite la dinum, et la DINUM est bien l’agence française du numérique). À une fenêtre décodeur de 256, le coût triple environ (~1,9 %) : c’est le point de rupture, et en dessous il continue de grimper. La fenêtre encodeur, elle, est largement surdimensionnée : la diviser par deux ne coûte presque rien.
Les résultats, sans arrondi
- 4 flux temps réel simultanés tenus 4,7 h sur une seule RTX 4090 Laptop 16 Go. La VRAM n’a bougé que de 54 Mo (< 0,4 %), et c’est une capture de graphe CUDA au préchauffage, pas une dérive. Cadence rigoureusement temps réel (temps écoulé / durée audio = 1,000 sur les quatre flux), kv_usage plat à ~0,38 en régime 4 flux, un nombre de ré-ancrages borné par construction, 0 erreur. 4,7 h, c’est le plus long run continu qu’on ait mesuré ; le mécanisme, lui, n’a pas de limite par construction.
- Le ré-ancrage ne dégrade pas la transcription, c’est mesuré. Test A/B (ré-ancrage ON vs OFF, fenêtre et extrait identiques, le ré-ancrage comme seule variable) sur quatre topologies de fenêtre, dont le cas le plus délicat des groupes fusionnés (256/256, 512/512) : écart de transcription de 0,00 % à 1,14 %, aucune substitution de sens, aucune boucle, aucun crash, jusqu’à ~260 ré-ancrages sur une exécution de 6 minutes. La seule divergence non nulle est une phrase de fin que le client n’a pas vidée, pas une corruption. La re-rotation R(−D) des clés en cache est transparente.
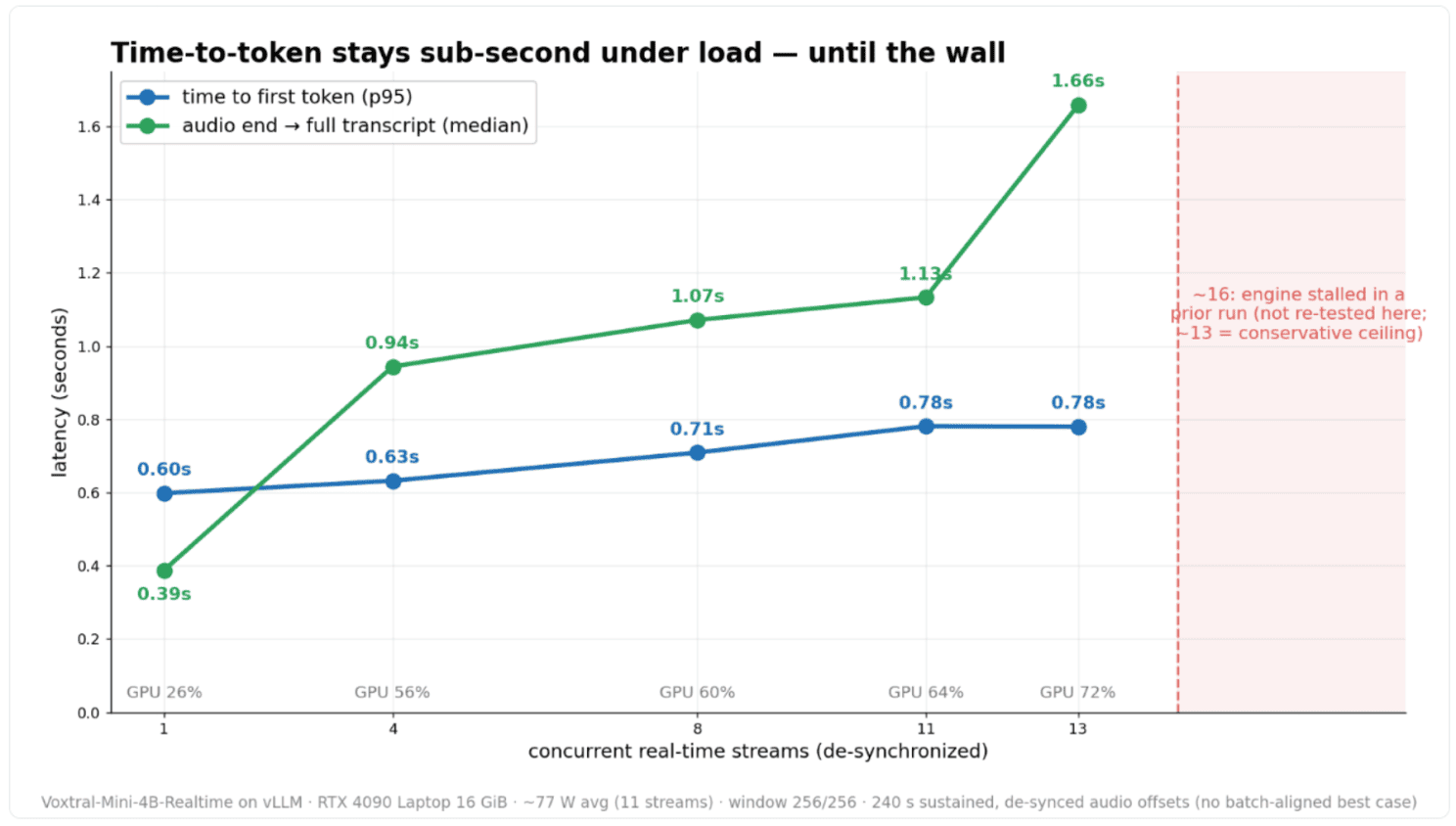
- Une montée de 1 à 13 flux désynchronisés a tenu le temps réel (chaque flux à un endroit différent de l’audio, pas le cas idéal des lots alignés). Chaque palier est une exécution de 240 s cadencée en temps réel, sur la même carte portable de 16 Go : temps écoulé / durée audio ≤ 1,007, 0 erreur, GPU de ~26 % à 72 % d’utilisation, à ~77 W de moyenne (à 11 flux).
- Le délai au premier token reste sous la seconde sur toute la plage, et c’est la métrique qui compte vraiment : premier token d’environ 0,6 à 0,8 s, fin d’audio à transcription complète d’environ 0,4 à 1,7 s, de 1 à 13 flux. La dégradation est douce, sans décrochage : le continuous batching de vLLM empile les flux remarquablement bien, et le modèle 4B est vraiment léger. (Mesuré à la fenêtre dense 256/256 ; le réglage de production recommandé, 512/256, privilégie la fidélité. Comme cette montée était bornée par le calcul, la fenêtre joue sur la fidélité, pas sur le nombre de flux. On est ici à quelques minutes par palier ; le multi-heures, c’est l’exécution 4 flux / 4,7 h plus haut.)
- Rien n’est perdu sous charge. À chaque palier, chaque flux a tenu sa session complète de 240 s, transcriptions partielles tout du long et transcription finale renvoyée, 0 erreur, temps écoulé / durée audio ≈ 1,0. Le « temps réel » ici, c’est le serveur qui suit la cadence du début à la fin, pas seulement au premier token. Chaque séquence décode indépendamment de ses voisines de lot, donc la transcription d’un flux sous charge est identique à sa transcription en solo. On a fait la vérification exacte sur l’image publiée : 4 flux simultanés sur le même audio ont chacun rendu les mêmes 2222 mots, écart nul, complets jusqu’à la 15ᵉ minute, 0 erreur.
- Le résultat sur la qualité reste préliminaire : un seul extrait français de 9 minutes ; un vrai WER avec référence humaine viendra ensuite.
- Le plafond de capacité est réel, et c’est un mur, pas une pente. ~13 flux désynchronisés tiennent le temps réel (mesuré à 256/256). Une session antérieure avait vu le moteur se figer vers 16, sur une saturation KV multi-session, une limite préexistante (dans le chemin de base, pas dans le ré-ancrage) que ce travail ne referme pas tout à fait. On retient ~13 comme plafond prudent sur cette carte ; on n’a pas re-testé 16, et 11 reste confortable. Surtout, ce plafond est borné par le calcul, pas par la mémoire : la VRAM reste plate (~15,4 Go) qu’on fasse tourner 1 flux ou 13, parce que la fenêtre fixe la KV par flux. C’est tout l’enjeu : dès que la mémoire cesse d’être le plafond, le nombre de flux suit le calcul de la carte. Ce GPU portable en tient ~11 à 13, une carte plus modeste comme l’A4000 en tient ~3 si elle est bien refroidie, une plus grosse davantage.
On a aussi mené une revue contradictoire, section par section, face à la branche main courante, pour mesurer le rayon d’impact sur les workflows non-Voxtral : sûr, avec une seule régression (le pooling à max_model_len) repérée et corrigée avant le merge, plus un test de non-régression ajouté.
Un mot sur la santé de l’écosystème open source
Commençons par le crédit, parce qu’il est réel. Voxtral realtime est vraiment ouvert (Apache 2.0), et le support vLLM est arrivé dès le premier jour : l’API realtime WebSocket (PR #33187) a été créée le 27 janvier et mergée le 30 janvier 2026, 5 jours avant le lancement, par l’équipe du modèle elle-même et avec une review de membres. Des correctifs continuent d’arriver (compat transformers ≥ 5.10, #44559, mergé cette semaine). Un modèle audio 4B sous Apache 2.0 avec le serving realtime intégré en amont le jour du lancement, c’est un engagement rare et concret. Rien de ce qui suit ne fait de procès d’intention.
Mais « tourne sur un seul GPU 16 Go » décrit la démo mono-flux, pas la production, et l’écart tient en trois points. C’est moins une histoire Voxtral qu’un schéma qui revient : comment un modèle ouvert atteint la production, ou n’y arrive pas.
1. Les recettes vous font acheter le mauvais GPU. Les configs de serving publiées convergent vers une seule commande : le guide « jour 1 » de Red Hat et l’aide-mémoire communautaire portent la même ligne à l’identique, --max-model-len 45000 --max-num-batched-tokens 8192 --max-num-seqs 16 --gpu-memory-utilization 0.90, testée sur A100. Regardez la forme : elle ne rétrécit jamais la fenêtre et associe un gros lot par étape à seize séquences, ce qui fait grossir la carte au lieu de borner le coût par flux. Sur un décodeur à fenêtre glissante, la KV par flux devrait être fixée par la fenêtre, pas élargie par le budget de lot puis multipliée par seize flux. Suivez cette recette pour de la vraie concurrence et vous voilà poussé vers un GPU de centre de données. Le benchmark multi-flux de la communauté conclut d’ailleurs qu’il faut « mieux qu’une seule RTX 4090 », et trois issues ouvertes (#38233, #39996, #38428) montrent des runs multi-session / longue durée qui font planter le moteur au lieu de se dégrader proprement.
2. Et c’est là qu’il y a une vraie facture, financière et écologique. Nous avons mesuré l’autre bout du spectre plus haut : onze flux en direct sous 80 watts sur cette carte portable de 16 Go, désynchronisés, chacun tenant le temps réel, en face d’une recette de référence validée sur A100 et d’une communauté qui conclut qu’il faut « mieux qu’une seule RTX 4090 ». Borner la KV par flux avec la fenêtre, c’est ce qui fait tenir la même concurrence sur une carte grand public au lieu d’une carte de datacenter : environ un ordre de grandeur sur le prix du GPU et plusieurs fois la consommation, par nœud, multiplié par chaque équipe qui copie-colle la recette. Du capex qu’on n’avait pas à payer, des watts brûlés pour rien, du silicium fabriqué pour rien. À l’échelle d’un parc, un défaut qui surdimensionne devient une taxe permanente, sur le budget comme sur le réseau électrique. Le revers est un vrai compliment à la pile logicielle : si ~77 W suffisent, c’est grâce à un modèle 4B léger et au continuous batching de vLLM qui fait remarquablement son travail. Le gâchis n’a rien d’inéluctable ; il tient au réglage par défaut, celui qui dit de dimensionner pour le pire cas. (Coût et consommation sont des ordres de grandeur, donnés à titre indicatif ; ce qui compte, c’est la direction.)
3. Et les correctifs qui combleraient l’écart sont restés ouverts. Début juin : #36015 (le gel silencieux) ouverte depuis mars, triée en quelques heures mais sans correctif de mainteneur livré ; un correctif communautaire, #36089, fermé sans avoir été mergé, son auteur notant « 7 semaines et plus sans review de mainteneur malgré une relance » ; #40072 (le crash à max_model_len) ouverte depuis avril avec une seule review automatique, un tiers signalant qu’elle est restée ~5 semaines coincée derrière un verrou CI « first-time contributor », « sans label de mainteneur ». Ces défauts sont dans vLLM, un projet communautaire géré par des bénévoles, pas dans le code de Mistral (le chemin realtime mergé, lui, vient de Mistral). C’est un problème de débit de review, pas de la malveillance. Mais le résultat est le même : les correctifs de production restent en suspens, pendant que le même modèle se vend sur une API hébergée (~0,003 à 0,006 $/min) qui, elle, fonctionne.
C’est la forme récurrente des sorties « ouvertes » : le vernis du jour J d’un côté, la maturité de production et sa facture matérielle de l’autre, laissée en exercice au lecteur. La bonne réponse, ce n’est pas un fil de récriminations : c’est un patch remonté en amont, coordonné avec les gens déjà sur ces fils. C’est ce qu’on a fait.
En attendant le merge, et un appel à contribuer
Nous n’attendons pas les bras croisés : ce fork tourne déjà en production chez LINAGORA, où il fait la transcription temps réel de notre plateforme open source LinTO.ai. Mais sa place est en amont, et c’est là que vous pouvez aider :
- Testez le fork. Démarrez-le avec la config bornée (--hf-overrides sliding_window + le flag sans limite de durée) et dites-nous comment il se comporte sur votre matériel et vos audios, surtout en multi-flux et longue durée.
- Relisez le code. C’est précisément ce dont il a besoin, parce qu’il touche des parties sensibles du cœur du moteur : la boucle d’ordonnancement WAITING/RUNNING et le garde-fou de plafonnement de longueur (partagés par tous les modèles), l’admission KV en fenêtre glissante, et la plus délicate, la re-rotation en place des clés KV déjà en cache par R(−D) côté worker, plus le découplage de l’horloge de positions RoPE de max_model_len. C’est ce rayon d’impact qui impose le flag désactivé par défaut et qui oblige à passer sans doute la barre RFC de vLLM.
- Soutenez-le. Un 👍, un retour d’usage concret sur les issues (#36015, #40072) et sur la PR : ça aide vraiment à franchir la RFC. Une issue ouverte le reste tant que personne ne montre qu’elle compte.
Fork : https://github.com/linto-ai/vllm ·
PR vLLM : https://github.com/vllm-project/vllm/pull/45022
docker pull lintoai/vllm:voxtral-realtime ·
LinTO.ai : https://linto.ai
Sources
- Annonce Voxtral (Mistral, 4 févr. 2026) : https://mistral.ai/news/voxtral-transcribe-2/ · Tarifs : https://mistral.ai/pricing/
- Fiche du modèle (Hugging Face) : https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602
- Recette vLLM : https://recipes.vllm.ai/mistralai/Voxtral-Mini-4B-Realtime-2602 · Guide « jour 1 » Red Hat : https://developers.redhat.com/articles/2026/02/06/run-voxtral-mini-4b-realtime-vllm-red-hat-ai ·
Aide-mémoire dougbtv : https://gist.github.com/dougbtv/f27d05fd6de68e07be3651c453bf37c7 - PR vLLM : #33187 (API realtime, mergée) · #44559 (compat, mergée) · #36089 (fermée, non mergée) · #40072 (ouverte) · #44461 (ouverte)
- Issues vLLM : #36015 · #35863 · #38233 · #38428 · #39996