Michel-Marie Maudet, Directeur Général et co-fondateur de LINAGORA, Bastien Masse, Délégué Général de l'Association ClassCode, et Olivier Gouvert, ingénieur de recherche chez LINAGORA, avaient donné rendez-vous !
Un moment très attendu par les membres de la communauté OpenLLM-France, les passionnés d’IA et d’Open Source, et tous les curieux désireux de connaître les avancées sur LUCIE : le tout premier modèle d’IA réellement Open Source, avec des données d’entrainement 100 % transparentes.
Plus d'une centaine de personnes se sont connectés à ce webinaire démontrant le réel intérêt et la pertinence de ce projet pour le numérique d'aujourd'hui.
Ambitions de la communauté OpenLLM-France
Le modèle LUCIE est cours de développement par l’initiative OpenLLM-France, lancée en été 2023 pour promouvoir des modèles de langage ouverts (LLM) et souverains. Cette initiative regroupe une communauté de plus de 800 acteurs publics et privés francophones et européens, incluant chercheurs, startups, et entreprises. Le but est de créer des communs numériques pour l'IA générative, en développant un modèle de langage accessible à tous.
Ce projet a d’ailleurs répondu à un appel de l'État français visant à soutenir la création de modèles de langage souverains, orientés vers des cas d’usage comme celui de l’Éducation. Parmi les partenaires figure notamment l’Association Class’code, un acteur du secteur de l'éducation, ainsi que des institutions académiques et ministérielles.
Le modèle que développe OpenLLM-France est pensé pour être plus ouvert et éthique. Contrairement aux modèles propriétaires, comme ChatGPT, ce modèle sera entièrement open source (sous licence APACHE V2) et les données d’entraînement seront également accessibles en Creative Commons non commerciale, garantissant la transparence et le libre accès.
L’objectif technique est de produire un modèle léger, sobre en énergie et facile à déployer, pour permettre une adoption plus large dans l’éducation, malgré des contraintes budgétaires.
Michel-Marie MAUDET, Directeur Général de LINAGORA et co-initiateur du projet, explique l'ambition du projet :
" Notre objectif c'est de développer un modèle de langage [...] sobre, compact, que l'on puisse utiliser assez simplement sans dépendre des grandes infrastructures que nous ne maîtrisons pas."
En résumé, OpenLLM-France vise à créer un modèle de langage accessible et indépendant, adapté à des besoins spécifiques, en s'appuyant sur une collaboration étroite entre acteurs publics et privés.

LINAGORA s’allie à Classcode sous la bannière d’OpenLLM-France
Class'code est une initiative créée en 2015 pour former les enseignants à la culture du numérique et à la programmation, via des ressources éducatives libres. L’Association a déjà produit de nombreux e-books et un MOOC en IA, accessible gratuitement. Elle a aussi participé à des projets européens, comme AI4O, pour étudier l’impact de l'IA en éducation.
Class'code travaille avec le GTNUM Génial, un groupe de travail soutenu par la Direction numérique pour l'Éducation et collaborant avec les académies de Versailles, Nantes et Marseille-Aix. L’objectif est de comprendre comment les enseignants et les élèves utilisent les IA génératives, d’identifier les défis d’évaluation, de protection des données, et d'approches pédagogiques.
Ainsi, l’initiative OpenLLM-France et Class’code répondent au besoin urgent d’outils opérationnels et éthiques pour exploiter l'IA en éducation, avec un LLM libre et un accompagnement de terrain pour former et outiller les enseignants.
Bastien MASSE, Délégué Général de Class'Code, explique
Notre objectif, c'était de réunir autour de la table des personnes de la recherche, des universités et d'autres acteurs pour produire des ressources de haute qualité. "
LUCIE, le modèle d’IA Open Source dédié à l’Éducation
Comme pour de nombreux secteurs, l’Éducation rencontre de nombreux défis liés à l’intégration de l’IA dans le parcours pédagogique des étudiants et enseignants, en particulier concernant le besoin d'acquérir des outils éducatifs fiables, respectueux des données et accessibles. Actuellement, il existe une multitude de solutions, mais peu sont adaptées aux exigences de l'éducation (stabilité, compatibilité avec la protection des données, documentation).
Lucie vise à répondre à ces besoins en offrant une bonne alternative, indépendante des grands acteurs commerciaux. Ce modèle est développé pour être stable et personnalisable, ce qui en fait un outil adapté aux EdTechs, enseignants, chercheurs et élèves. Il permettrait notamment des applications comme le RAG (Recherche Augmentée par l’IA) pour les enseignants, en utilisant des références fiables pour limiter les erreurs et les biais. Les enseignants pourraient ainsi intégrer leurs propres contenus de manière sécurisée et contrôlée.
Une version de petite taille du modèle (autour de 1 milliard de paramètres) sera également développée plus tard afin de permettre une utilisation du modèle en local sur des ordinateur de faible puissance. Rendant également possible un portage du modèle sur des devices de type Raspberry ou mini computer pour un usage sécurité sans réseau ni échange d’information serveur.
Le modèle LUCIE se distingue par sa sobriété, sa compacité et son respect de l'IACT, la réglementation européenne pour une IA de confiance. Conçu pour être entièrement Open Source, Lucie est libre d’utilisation, même commerciale, et tous les éléments (datasets, code) sont accessibles, permettant une transparence totale.

L’entrainement de LUCIE
L’entraînement de ce modèle a commencé en août sur les infrastructures du CNRS : le supercalculateur Jean Zay, du GENCI, avec l’ambition de traiter 3 000 milliards de tokens pour lui fournir une vaste base de connaissances. Ce qui nécessité l'utilisation de 512 GPU H100 en parallèle et la collecte d'un jeu de donnée massif
" Sans trop divulguez les chiffre, on est sur 3000 milliards de tokens, on est sur de très grandes volumétries que l'on va mettre à disposition dans le cadre de cette démarche"
Michel-Marie MAUDET
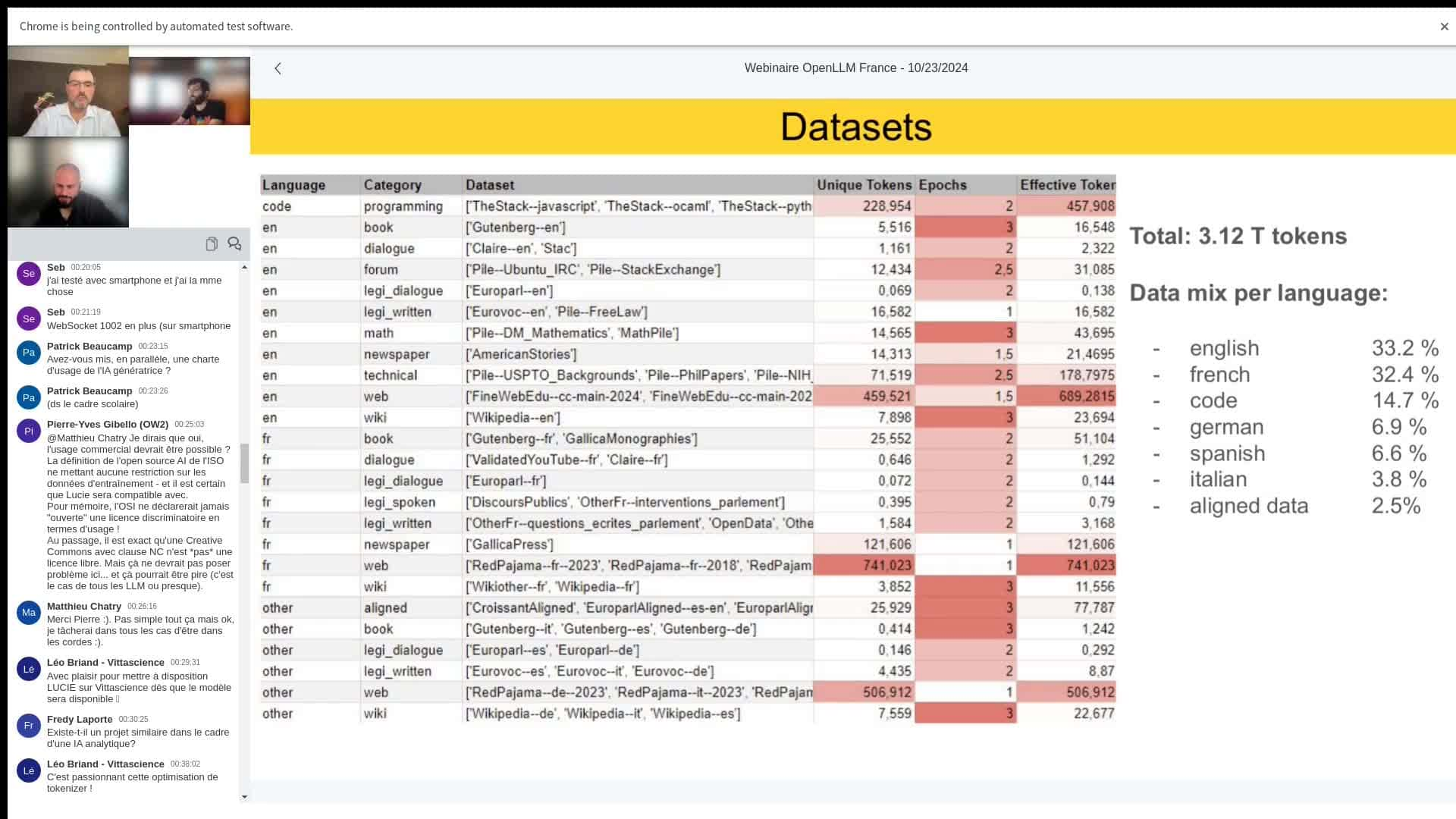
- Composition des données : Pour obtenir un modèle performant, Lucie est entraînée sur un mélange de langues et de types de données : anglais (33 % ), français (32,4 %), du code informatique et des mathématiques (15 %) car ils améliorent les capacités de raisonnement du modèle. Les autres langues comme l’allemand, l’espagnol et l’italien complètent les 20 % restants. Ainsi, chaque type de données est pondéré différemment pour prioriser la qualité (ex. : les données de Wikipédia sont vues plusieurs fois) et diversifier les compétences linguistiques du modèle.
- Filtrage des données : Afin d’assurer une qualité optimale, un filtrage strict est appliqué. Les données sont sélectionnées selon des critères de qualité pour éviter les informations redondantes, erronées ou offensantes. Par exemple, les URL de sites jugés offensants ou non pertinents sont exclus, et les contenus avec des mots bannis sont filtrés. Un processus de "near deduplication" est également employé pour éliminer les répétitions et garantir l’unicité des données.
Ordonnancement des données et parallélisme d’entraînement : L’entraînement de Lucie se déroule en utilisant des GPU en parallèle et en appliquant une technique de parallélisme "3D" pour optimiser le processus. Les données plus anciennes sont traitées en début d’entraînement, ce qui permet de recentrer le modèle sur des informations actualisées en fin de parcours. Ce choix aide Lucie à maintenir des connaissances récentes.
Olivier GOUVERT, ingénieur de recherche chez LINAGORA, explique :"Nous avons moins de mal à accepter qu’il oublie des choses sur des données qui sont vieilles"
- Extension de la fenêtre de contexte : Lucie est en phase d'expansion de sa fenêtre contextuelle, de 4 096 à 128 000 tokens, permettant de mieux traiter les longs textes sans coupures. Cette capacité est cruciale pour des applications nécessitant une grande contextualisation, comme les systèmes de RAG. Par exemple, dans une application de questions-réponses pour une entreprise, cela permettrait au modèle de consulter un document d’entreprise entier, enrichissant ainsi la pertinence de ses réponses.
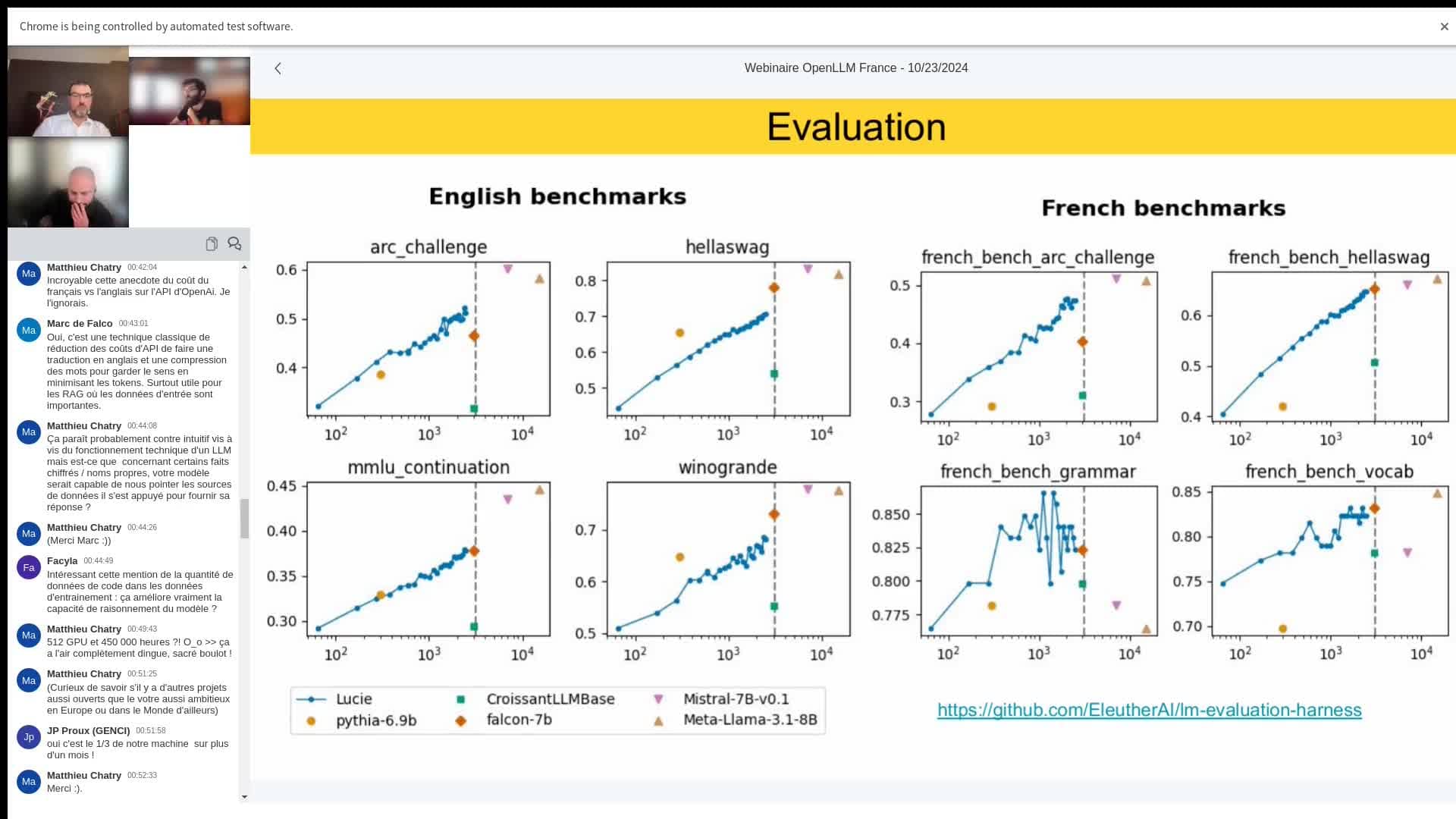
Evaluation et comparaison des performances : Lucie est comparée à d’autres modèles comme Pythia, Croissant LLM et Falcon, sur des benchmarks français et anglais. Sa performance progresse de manière logarithmique, et les résultats montrent des prévisions prometteuses. À gauche du graphique, les benchmarks anglais montrent les étapes de progrès de Lucie par rapport à des modèles majoritairement anglophones, tandis que les benchmarks français soulignent sa compétence accrue dans cette langue.
Olivier GOUVERT souligne :" On voit que notre tokenizer est adapté pour ces 5 langues qu'on a choisi pour représenter un peu la diversité des langues européennes, ainsi que pour le code. "
6. Phase d'instruction et d'alignement : Afin d'améliorer ses réponses et de les aligner sur les attentes humaines, Lucie passe par une phase d'instruction en deux étapes :
Fine-tuning (ajustement fin) : Cette première étape consiste à ajuster le modèle sur des données de type questions-réponses, plus proches de discussions humaines.
Par exemple, des jeux de données spécifiques sont créés avec des questions simples comme « Quelle est la capitale de la France ? », et des réponses précises sont fournies. Ce processus enseigne à Lucie qu’elle doit fournir une réponse directe, comme « Paris », explique Olivier.
- Apprentissage par renforcement : Dans cette seconde étape, Lucie génère plusieurs réponses pour une même question, et celles-ci sont évaluées. Les préférences humaines sont ensuite intégrées pour affiner ses futures réponses.
Actuellement, le modèle Lucie est soigneusement entraîné avec une combinaison de données multilingues, un filtrage méticuleux et des stratégies avancées d'entraînement. Cela garantit un modèle final à la fois diversifié et performant pour des tâches de compréhension complexe et de génération de texte.
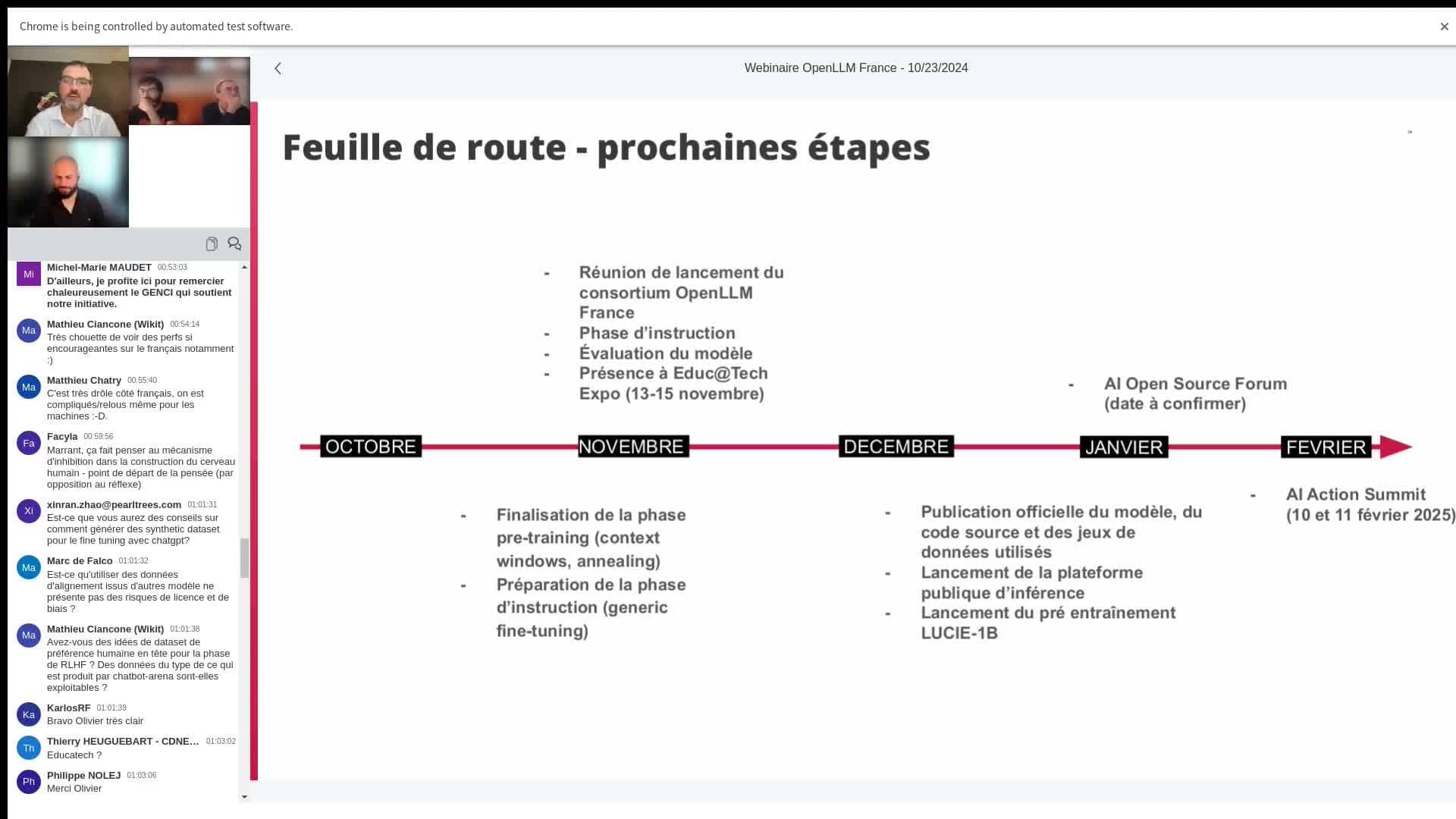
La suite des événements ...
Michel-Marie MAUDET évoque les prochaines étapes :
" On prévoit ça vraiment tout début décembre. Il y aura à la fois la publication du modèles, des data-sets, du code source et toute la sauce qu'on a utiliser pour entraîner le modèles. "
Les équipes d’OpenLLM-France travaillent pour le moment à finaliser et à pré-instruire Lucie, en visant un modèle final d’ici fin novembre. La mise à disposition publique est prévue début décembre, avec une publication de toutes les ressources, comme le code source, les datasets, et les méthodes d'entraînement, en collaboration avec Hugging Face.
Lucie sera disponible sur cette plateforme, accompagnée d’une API gratuite pour les tests. Les utilisateurs pourront ainsi tester ou télécharger le modèle pour l’utiliser sur des outils locaux comme Ollama et LM Studio.
Un accès sera également possible à travers la plateforme Vittascience, Edtech partenaire du projet, qui propose déjà des activités de médiation scientifiques sur l’IA. Permettant un accès pour les élèves et les enseignants sans nécessité de se connecter.
LINAGORA prévoit aussi une plateforme SaaS avec un modèle d'abonnement pour utiliser Lucie, permettant de couvrir les coûts d’infrastructure, principalement dus aux GPU nécessaires.
Une version allégée du modèle à 1 milliard de paramètres est aussi en cours de préparation. Celui-ci vise une utilisation sur des appareils mobiles, y compris les téléphones, pour rendre l'accès aux grands modèles de langage possible dans un contexte local.
Toutes les informations, y compris le code source, seront disponibles sur le GitHub de la communauté : https://github.com/bentoml/OpenLLM